
Stable Diffusionを使って、自分のイラストを追加学習(ファインチューニング)させ生成する方法を紹介したいと思います。いつもと同じように、細かい話は抜きにして、このまま実行させればできるように紹介したいと思います。環境はWindows11です。
事前準備
StableDiffusionに関しては、導入方法、コピー機LoRAの作成と紹介してきました。もし環境の立ち上げがまだという方は、まず下記の記事を参考にして、環境の立ち上げをお願いします。
このまま実行すれば出来る! Stable diffusionの導入手順を簡単に説明します。
【Stable Diffusion】Kohya GUIの導入方法、コピー機LoRAの作り方を簡単に説明します。
自分のイラストとタグファイルの準備
それでは、一番重要な、イラストの準備をします。私はイラストが描けないので、妻に書いてもらいました。とりあえず14枚。また、全イラストに対し、タグを準備します。
画像とタグのファイル名は同じにします。こんな感じ↓

タグファイルは、その画像の特徴を示す言葉を「,」で区切ってい記載していきます。このタグはいろいろな手法がありますが、今回は枚数も少なく特徴も少ない画像ですので、すべて手作業で作っています。
例えば「1.txt」の中身はこんな感じ
yamaseeotto, man, greyscale, monochrome, solo, short hair, black hair, white background, Laughing mouth, Face front, Smiling, normal hairstylekohya_ssを使って学習準備
基本的な学習の方法は、下記のコピー機LoRAと同じです。
【Stable Diffusion】Kohya GUIの導入方法、コピー機LoRAの作り方を簡単に説明します。
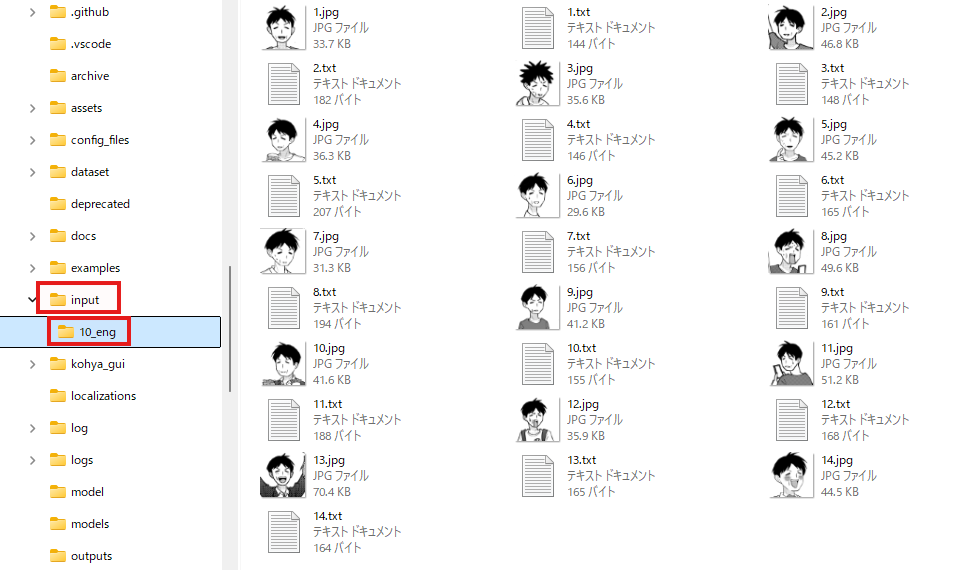
下の例の用に「kohya_ss」フォルダ直下に「input」というフォルダを作成、その下に「10_eng」というフォルダを作成し、準備した学習画像とタグファイルをすべて入れます。
この「10_eng」というフォルダ名ですが、はじめにつけた数字が、学習の繰り返し回数を表します。
LoRAの学習においては、次の式で学習ステップ数が計算され、LoRAでは2000~5000ステップが目安とされています。
画像枚数 X 学習の繰り返し回数 X Epoch数 = step数
今回の例だと、画像枚数14枚 学習繰り返し数 10回としましたので、Epoch数は35くらいがよいでしょう。
画像枚数14枚 X 学習繰り返し数 10回 X Epoch数35 = 4900ステップ
学習に使うモデルの準備
追加学習ですので、元の学習モデルを準備します。今回はイラスト系で人気のモデルの1つ、「AnyLoRA」を使ってみます。それぞれのイラストに合わせてお気に入りのモデルを使ってください。
AnyLoRA – Checkpoint – bakedVae (blessed) fp16 NOT-PRUNED | Stable Diffusion Checkpoint | Civitai
上記を開くと、ダウンロードするところが見えると思いますので、ダウンロードお願いします。

ダウンロードしたモデル、任意の場所に格納しますが、私の場合は、StableDiffusionのフォルダにモデルは集めていますので、「\StableDiffusion\stable-diffusion-webui\models\Lora」ダウンロードした「anyloraCheckpoint_bakedvaeBlessedFp16.safetensors」のファイルを格納しました。
kohya_ssの設定
それではkohya_ssを起動し設定していきます。
まずは、「gui.bat」をダブルクリックして起動します。
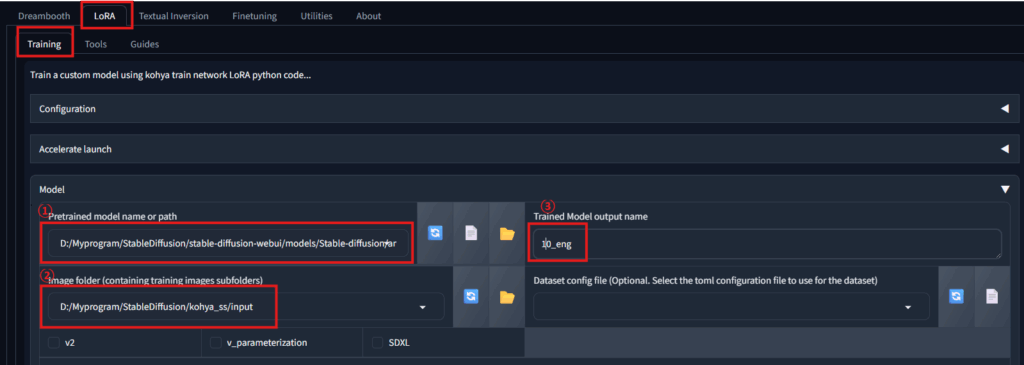
下の図のように、「LaRA」→「Training」と進み、
①先ほどのモデルを指定
②学習データを格納したフォルダのパス。今回だと、「10_eng」フォルダの1つ上の階層です。
③Outputのファイルの名前を任意に指定
Output フォルダのパスを指定。こちらも任意のパスで構いません。

Epoch数は先ほど決めた35。それに合わせ、Save every N epochsも35。
Max train Stepsは0にしておきます。

DimensionとAlphaはとりあえず32と2。環境によって変わります。高い性能のGPUを持っている方は数字をあげ、そうでない方はこのくらいがよいでしょう。

Clip skipを2にします。

・ここまで出来たら、一番下のStart trainingを押しましょう。

・学習が始まると、こんな感じに動きます。
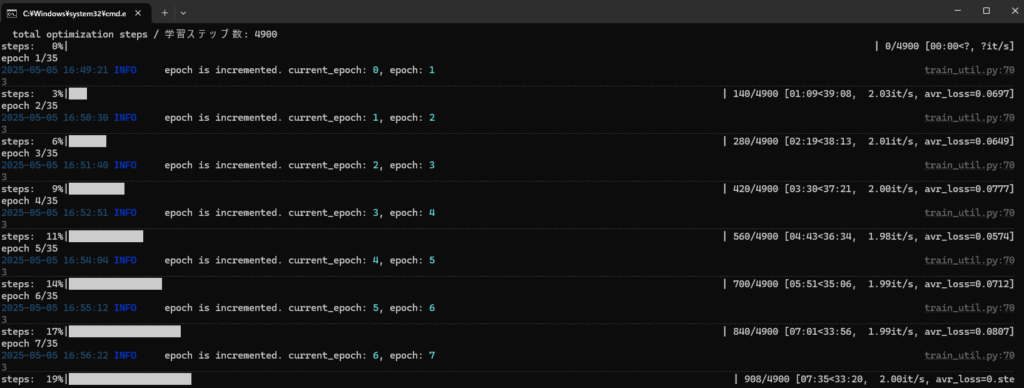
学習が終わると、Training has ended と表示されます。

学習結果の確認
LoRAの画面で指定した「outputs」フォルダを見てみます。「10_eng.safetensors」ファイルができていれば成功です。

・このファイルを「stable diffusion」のLoraフォルダへコピー。下のパスです。
\StableDiffusion\stable-diffusion-webui\models\Lora
・Stable difusionを起動。↓のパスのwebui-user.batをダブルクリック
GUIが起動します。起動しない場合は、コンソール画面に次のように表れている、URLをコピーして、ブラウザに直接入力してください。「http://127.0.0.1:7861」
左上でCheckpointを選択。学習の時に使ったものを選ぶので、今回の場合は、「anyloraCheckpoint_bakedvaeBlessedFp16.safetensors」を選びます

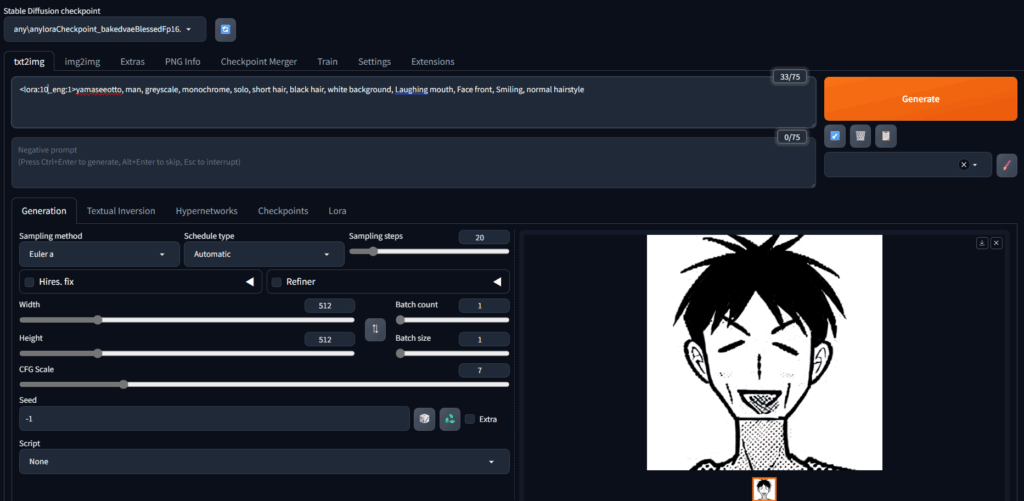
そして、txt2imgのところに、このように入力します。
<lora:10_eng:1>yamaseeotto, man, greyscale, monochrome, solo, short hair, black hair, white background, Laughing mouth, Face front, Smiling, normal hairstyle
<lora:10_eng:1>黄色部分は生成したファイルの名前
<lora:10_eng:1>赤部分は何%追加学習のイメージで生成するか?の数字で、1の場合は100%追加学習の画質を利用する場合です。
<lora:10_eng:1>yamaseeotto, man, greyscale, monochrome, solo, short hair, black hair, white background, Laughing mouth, Face front, Smiling, normal hairstyle
青の部分はプロンプトで、今回の例では、学習データと全く同じにしていますが、いろいろ変えてみると面白いでしょう。
そしてGenerateを押せば完成。
試しに、<lora:10_eng:1> の赤部分の割合を変えてみましょう。10%だともはや原型なし。

すべての学習画像と生成AIを比べるとこんな感じ。
これを見ると、やり方が悪いのか、生成AIまだまだですねぇ。画が汚い。
オリジナル↓














生成↓
















コメント