
YOLOのv11では、「物体検出」、「インスタンス分類」、「画像分類」、「姿勢推定」、「指向性物体検出」の機能が利用できます。その中で、本記事では、インスタンス分類(インスタンス セグメンテーション)について、この記事にまま実行すれば出来るくらいにかみ砕いて説明しようと思います。
事前準備
Yoloを実行するには、事前準備が必要で、この準備が結構大変。以前の記事で、そのまま実行すれば出来るレベルで書いた記事があるので、事前準備がまだという方は下記の記事で、Python、YOLO、VisualStudioCodeのインストールを実行してください。
このまま実行すれば出来る。YOLO v11を使った物体認識の方法教えます。
モデルのダウンロード
上記セットアップが完了したら、準備されているモデルをダウンロードします。追加学習のできますが、それは別途記載するとして、今回はデフォルトの学習モデルをそのまま活用します。
下記リンクへ移動してください。
https://docs.ultralytics.com/ja/tasks/segment/#models
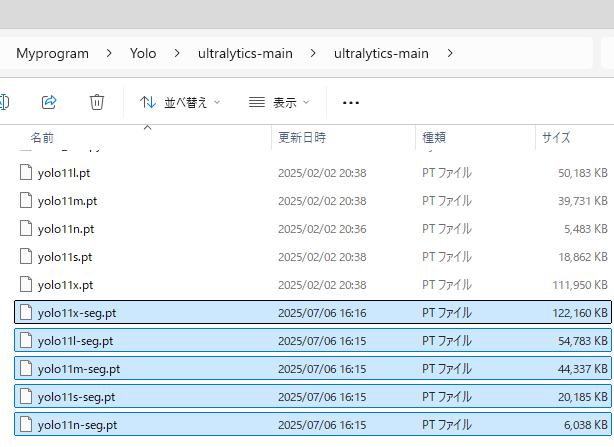
すると下のような表がありますので、赤枠で囲っている部分をクリックし、すべてダウンロード

ダウンロードしたファイルは、下記でGitからクローンしたフォルダの中へ格納。
このまま実行すれば出来る。YOLO v11を使った物体認識の方法教えます。
こんな感じです。
そして、セグメンテーションしたい適当なファイルを同じフォルダへ格納。この記事の例では、とりあえず、この有名な画像をダウンロードして格納します。
https://ultralytics.com/images/bus.jpg
プログラム作成と実行
次にプログラムの作成。
VisualStudioCodeやテキストで次のPythonコードを記入。任意の名前で↑と同じディレクトリに保存。
今回は、「yolo_seg_test.py」としました。すぐ実行したい方は、下記のプログラムを下記を丸々コピーしてください。
from ultralytics import YOLO
# Load a model
source = "bus.jpg"
model = YOLO("yolo11x-seg.pt") # load an official model
# Predict with the model
results = model.predict(source, save=True, imgsz=320, conf=0.5)このプログラムを実行します。
pythonの仮想環境の作り方も下記参照
このまま実行すれば出来る。YOLO v11を使った物体認識の方法教えます。
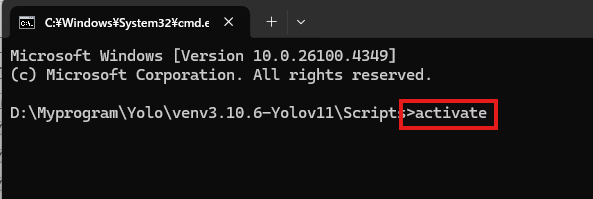
仮想環境を起動します。
仮想環境フォルダ直下の「Scripts」フォルダまで行って、このように「cmd」と入力すると、そのパスでコマンドプロンプトが開くので便利です。
実行するとこんな感じ
activateします↓
yolo_seg_test.pyと画像ファイルが入っているフォルダに移動、この例では、yoloをクローンしたフォルダ直下に置いているので、下記。

実行

GPU性能によりますが、少し時間たって、終了。
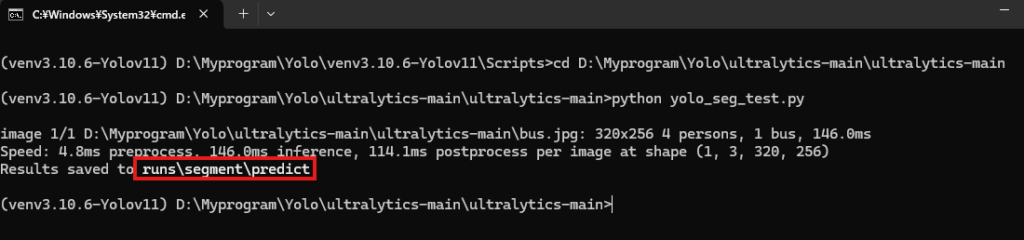
上の赤枠のところに結果が格納されているフォルダが見えるのでそこを除きに行きます。
↓ありました。
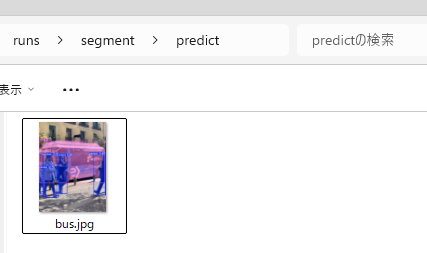
結果の画像はこれ。バスや人がセグメンテーションされて、色分けされている事がわかります。

もう一つ、以前「StableDiffusion」で生成したこの画像でセグメンテーションしてみようと思います。「StableDiffusion」に関しては下記の記事を参照お願いします。
このまま実行すれば出来る! Stable diffusionの導入手順を簡単に説明します。
【Stable Diffusion】Kohya GUIの導入方法、コピー機LoRAの作り方を簡単に説明します。
StableDiffusion 自分のイラストを追加学習させる方法を簡単に紹介します
生成した画像は下記。

これを、セグメンテーション実行した結果は下記。ちゃんとセグメンテーションできてますね。



{kind=link}
コメント