
Yoloのv11を使った物体認識の追加学習(Fine tuning)の方法を説明していきます。自前の画像を使うこと、OSはwindowsという前提での説明を、いつものようにこの手順のまま実行していけばできるようにまとめていきたいと思います。
アノテーションとは
前回の記事で、Yoloの物体認識の手順を説明しましたが、物体を認識するときに「person」とか「bus」とか認識結果で表示されたと思いますが、これはYoloのデフォルトのアルゴリズムにおいてアノテーションがされているからです。
アノテーションとは、その画像が何なのかを紐づける事で、人の写真を学習データとして、「person」とアノテーションすると、類似の画像を読み込んだ時、「person」の確立がどのくらいあるかを結果として表示します。
例えば「person 0.82」という表記は82%の確立で「person」である。という意味になります。

↑のサイトのリンクの手順で実行したときの学習モデルは、デフォルトいくつか分類がされていますが、それ以外のものを分類したいときは、追加学習をしてあげる必要がありますので、
そのアノテーションの方法と、追加学習の方法を、本記事では記載していきます。
labellmgの使い方
それでは、ここではLabelingを使ったアノテーション方法を説明していきます。他にもVoTTなどの手段もありますが、今回は「labelImg」
Windowsを使っている方はこちらからインストールが簡単です
https://github.com/HumanSignal/labelImg/releases/tag/v1.8.1
下記をクリックして、ダウンロードしてください。
解凍すると、次のファイルが見えますので、任意の位置へ格納

labellmg.exeをダブルクリックすると次のWindowが現れます。
これを使う前に、画像フォルダとアノテーション結果を入れるフォルダを作っておきます。
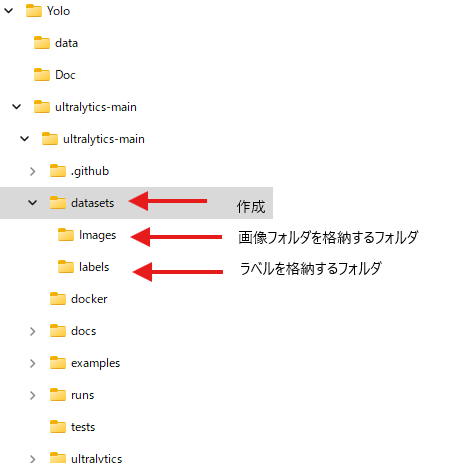
このような感じで作りましょう。私の場合はYoloを格納しているフォルダの第一階層に「datasets」を作成し、その下に次の2つのフォルダを作成
「Images」画像を格納するフォルダ
「labels」ラベルを格納するフォルダ
画像フォルダには、以前StableDiffusionで生成した、私の似顔絵を入れました。

StableDiffusionに興味がある方は下記参照お願いいたします。
このまま実行すれば出来る! Stable diffusionの導入手順を簡単に説明します。 – エンジニア大学
【Stable Diffusion】Kohya GUIの導入方法、コピー機LoRAの作り方を簡単に説明します。 – エンジニア大学
それでは続きを説明します。
手順1:OpenDirで上の手順で作成した、「画像を入れるフォルダを指定」
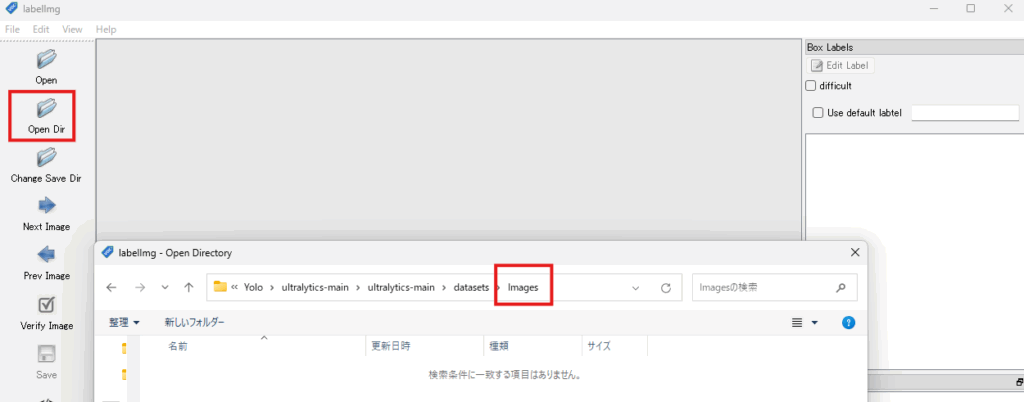
そうすると、このようにそのフォルダに入っている画像が表示されます。
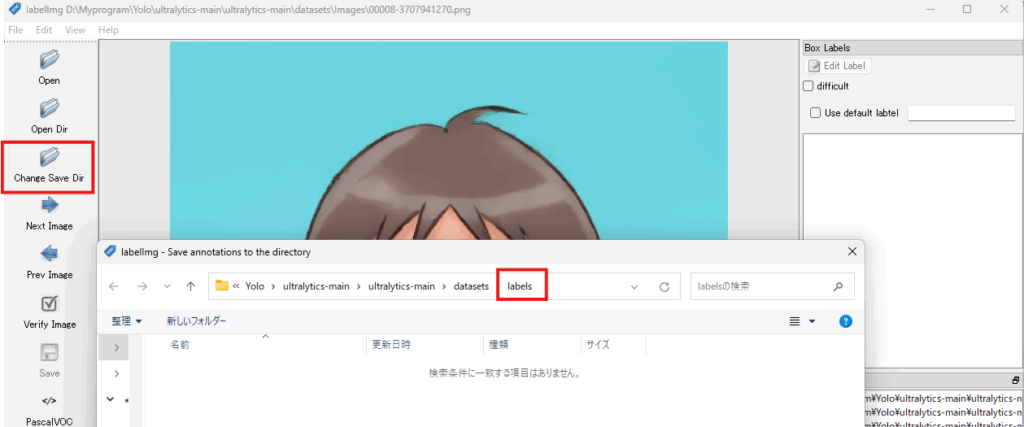
手順2:「Change Save Dir」でラベルを保存するフォルダを指定
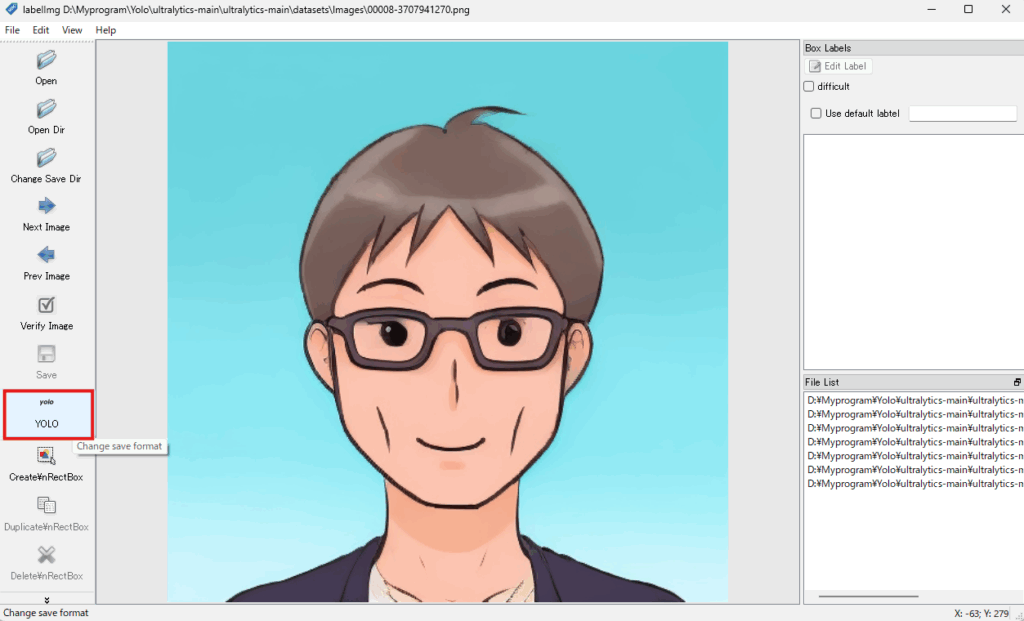
手順3:下記の赤枠の部分をクリックして、「YOLO」に変更します
それではアノテーションしていきます。
手順4:画面上で右クリックすると、下の表示が出てきますので選択
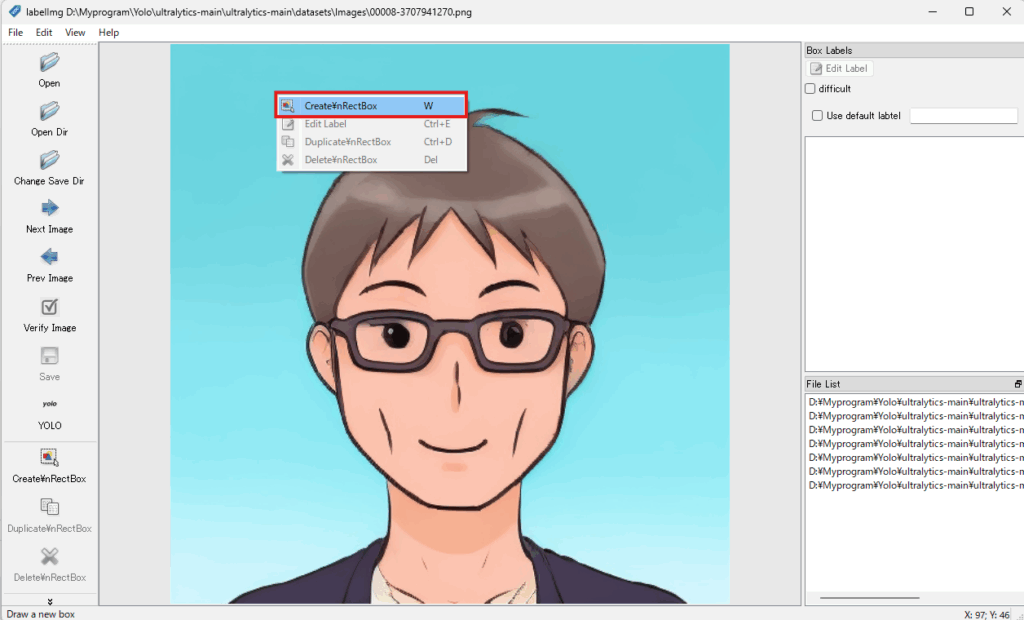
手順5:アノテーションしたいエリアを囲み、ラベル入力画面がでてくるので、記入します。
ここでは、取り合えずエンジニア大学の「ENG」と適当に入れました。
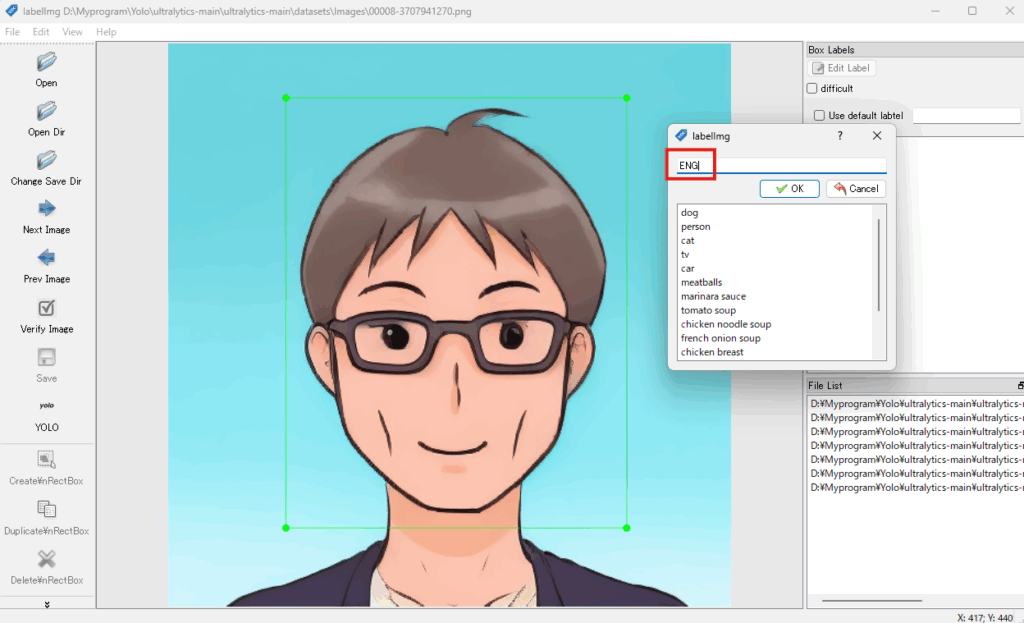
手順6:ラベルを入力したら、保存
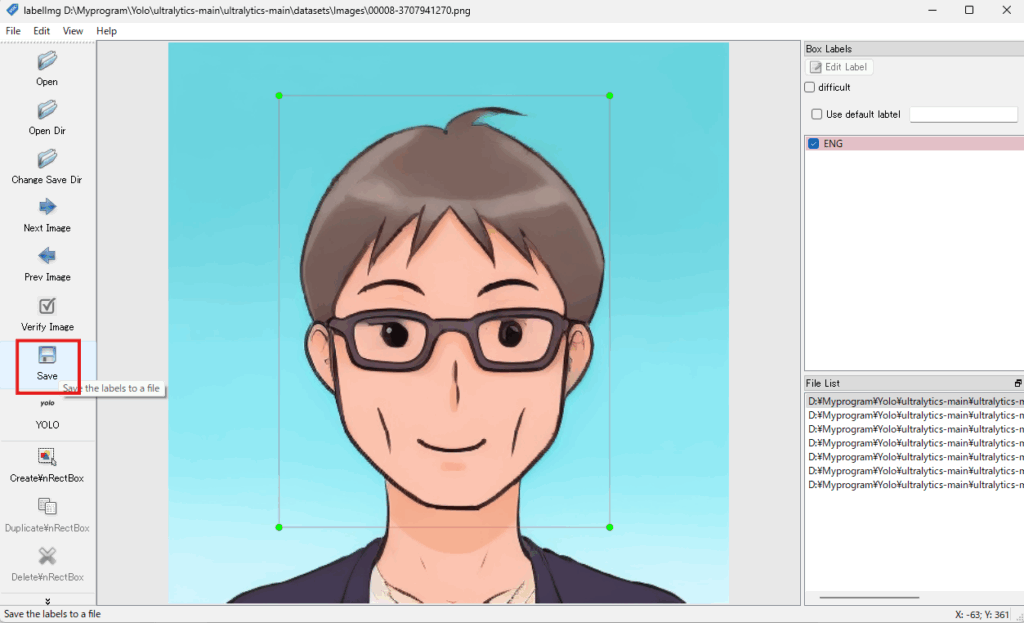
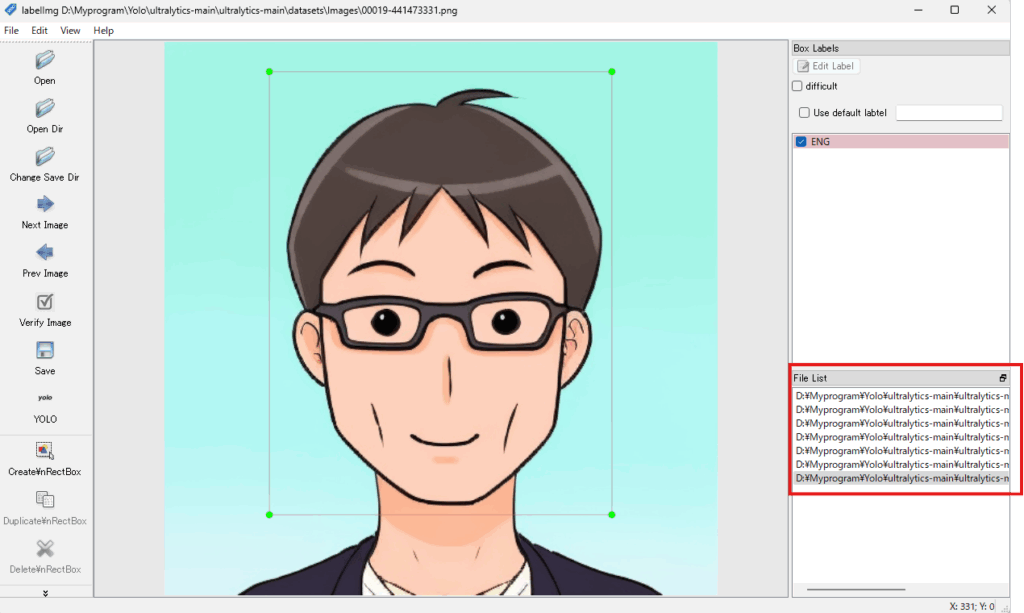
手順7:この作業を右下のFileListの画像をダブルクリックして、アノテーションしたいすべての画像で実施します
先ほど作成した、labelsフォルダに次にように、画像の名前事のtxtファイルと「classes.txt」ファイルができていれば正解です。
これでアノテーションは終了。
追加学習
それでは、学習の手順に移りたいと思います。
手順1:次のようにフォルダを構成します。
下記、Topフォルダ以下のディレクトリ構成とフォルダ名は変更しないでください。フォルダ名を変えるとうまく動きません。

手順2:アノテーションした画像とラベルを上記フォルダへ振り分け
imagesのtrainとvalへ画像を格納
学習用と評価用はおおよそ8:2くらいの割合で。今回の例は20枚の生成画像でトレーニングしましたので、15枚を学習用、5枚を評価用としました。
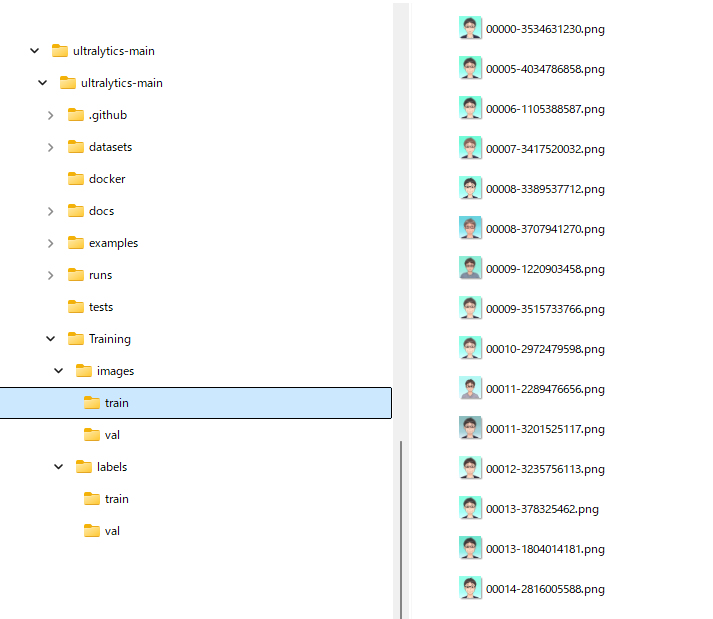
labesフォルダへはアノテーションしたときに生成された.txtを格納。
※画像と同じ名前で生成されているので、学習と評価への分配は画像データと合わせてください
手順3:yamlファイル作成
学習で使う、yamlファイルを作成します。
Classesの部分は、labellmgを使い、アノテーションすると、ラベルと同じフォルダに「classes.txt」というファイルができていると思いますので、それをコピーして、下の例のように番号をふってください。
一番上のパスは、手順2で作ったパスを指定。
path: D:\Myprogram\Yolo\ultralytics-main\ultralytics-main\Training\images # dataset root dir
train: train # train images (relative to 'path')
val: val # val images (relative to 'path')
# Classes 0-14はlabellmgを使うと自動的に出来上がっている
names:
0: dog
1: person
2: cat
3: tv
4: car
5: meatballs
6: marinara sauce
7: tomato soup
8: chicken noodle soup
9: french onion soup
10: chicken breast
11: ribs
12: pulled pork
13: hamburger
14: cavity
15: eng #追加
手順4:学習の実行
手順3のyamlファイルのパスを指定して、次のように.pyファイルを作成。yamlファイルの名前は「org.yaml」としました。また、ベースとするモデルを指定する必要がありますが、今回は、「yolo11x.pt」としています。
「imgsz」は画像のサイズを指定しますが、この記事の学習データが512×512のサイズですので、このように設定しています。
※画像サイズは学習データに合わせる必要なく、リサイズ後のサイズです。GPUメモリに余裕がない場合は、サイズを小さくしてください。
epoch数は「学習データ全体を何回繰り返して学習させるか」の数です。今回は学習データが非常に簡単なので適当に100にしていますが、学習データの種類などにより、増減させてください。
from ultralytics import YOLO
if __name__ == '__main__':
# ベースとするモデル
model = YOLO('yolo11x.pt')
#GPUを使ってモデルを学習
results = model.train(
data=r'D:\Myprogram\Yolo\ultralytics-main\ultralytics-main\org.yaml',
epochs=100,
imgsz=512,
device=0 #GPUの場合0
)
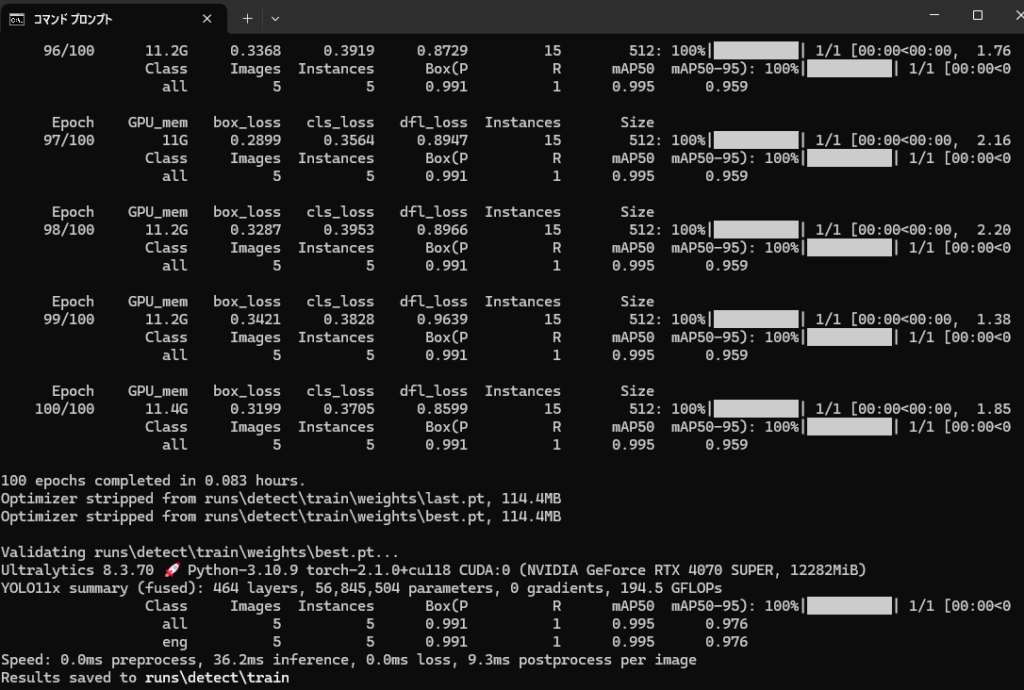
上記を実行すると、トレーニングが始まります。
完了すると、下のように表示
手順5:学習結果の確認
学習結果は、「\runs\detect\train」の中に入っています。そのフォルダ内「weights」フォルダを見ると、「best.ps」「last.ps」のファイルがあるのがわかると思います。
bestは学習を繰り返す中で、一番性能が上がっているときのデータ。
lastは最後の学習のデータです。
これらを使って、結果を確認してみましょう。
プログラムはこのように作っています。
下記コードのsourceは、確認に使う画像データの名称を入れてください。
from ultralytics import YOLO
# Load a model
source = "00020-1017105739.png"
model = YOLO("best.pt") # load an official model
# Predict with the model
results = model.predict(source, save=True, imgsz=512, conf=0.5)実行すると、「\runs\detect\predict」に結果が保存されます。
「best.pt」の結果↓

「last.pt」の結果

lastは96%の確率と言っているのに対し、bestは100%の確率と言っていますので、bestの方が性能が良いことがわかります。
※ただ、今回は同じような画像を入れているのと、学習枚数も少ないため、あくまで手順説明用として、性能は無視してください。
アノテーションが面倒くさいという方は下記に既存データを活用したやり方も載せています。
このまま実行すれば出来る。YOLO v11を使って、顔認識(face detection)を追加学習させてみよう。


コメント